





Par Emmanuel Forgues
![]()
Acheter la convergence (VCE, VMware, EMC) ou l’Hyper-convergence (VCE, Nutanix, Simplivity, Atlantis) aujourd’hui pour respirer le futur
Délivrer l’IaaS comme fondation de l’ITaaS
 Pour reprendre et donner une prolongation à l’article de Noham « Pourquoi conduire la transformation de l’IT est aujourd’hui un incontourable ? » : Il y a quelques temps les fournisseurs externes arrivaient à être plus précurseurs que les départements informatiques des entreprises, poussant les utilisateurs à expérimenter eux-mêmes les nouvelles options qui s’offraient à eux comme le Cloud Public. Avec un usage de plus en plus large des technologies et services externes à l’entreprise, les utilisateurs on fait apparaitre des risques considérables pour l’entreprise, créant par la même occasion un nouveau marché : le shadow IT (l’IT cachée). La convergence de ces nouvelles tendances et le sursaut des DSI pousse à voir apparaitre une nouvelle tendance : l’ITaaS (IT As A Service) ou l’ensemble des services de l’IT peuvent être proposés comme un service externe rétribué à l’usage et prenant en charge les besoins des utilisateurs ‘hors-control’ par le DSI. Dans cette course au besoin et aux réponses, les DSI peuvent prendre une longueur d’avance considérable et innovante.
Pour reprendre et donner une prolongation à l’article de Noham « Pourquoi conduire la transformation de l’IT est aujourd’hui un incontourable ? » : Il y a quelques temps les fournisseurs externes arrivaient à être plus précurseurs que les départements informatiques des entreprises, poussant les utilisateurs à expérimenter eux-mêmes les nouvelles options qui s’offraient à eux comme le Cloud Public. Avec un usage de plus en plus large des technologies et services externes à l’entreprise, les utilisateurs on fait apparaitre des risques considérables pour l’entreprise, créant par la même occasion un nouveau marché : le shadow IT (l’IT cachée). La convergence de ces nouvelles tendances et le sursaut des DSI pousse à voir apparaitre une nouvelle tendance : l’ITaaS (IT As A Service) ou l’ensemble des services de l’IT peuvent être proposés comme un service externe rétribué à l’usage et prenant en charge les besoins des utilisateurs ‘hors-control’ par le DSI. Dans cette course au besoin et aux réponses, les DSI peuvent prendre une longueur d’avance considérable et innovante.
Avant d’en arriver à choisir l’ITaaS (IT as a Service) il faut commencer par la base et choisir son infrastructure pour répondre aux besoins des développeurs (Dev) et de l’opérationnel (Ops). Les logiciels et le matériel doivent offrir :
- la mise à disposition d’environnement rapidement en mode self-service
- tous les mécanismes d’automatisations associés
- l’identification des couts (refacturation transparente des coûts)
- sécurisation : encryption, authentification, contrôle des accès
- évolutivité possible (d’autres Hyperviseurs par exemple)
La partie logicielle a déjà été abordée dans l’article sur l’association de l’hyper-convergence et des entreprises pour répondre au besoin du DevOps, nous abordons dans celle-ci le choix de l’infrastructure et ses critères. Néanmoins, il ne faut pas perdre de vue que l’infrastructure se verra totalement masquée par tous les services additionnels pour faire bénéficier à l’entreprise l’expérience du SDDC. Par extrapolation, l’importance du type de matériel est très faible à partir du moment où il délivre le service demandé. Il saura se rappeler à votre mémoire lorsqu’il ne sera pas possible d’en augmenter les ressources, en cas de panne, pour des migrations impossibles ou compliquées et autres actions classiques sur une infrastructure.

Choix du socle de l’infrastructure
Nous avons assisté il y a de cela quelques années à une grande phase d’optimisation des infrastructures avec la virtualisation. En virtualisant les serveurs physiques nous avons assistés à un gain conséquent de toutes les ressources dans les entreprises (humains, financiers, énergétiques, etc…). Dans un premier temps avec la virtualisation des services puis la virtualisation du stockage avant d’aborder la virtualisation des réseaux (dernière étape peu démocratisé).

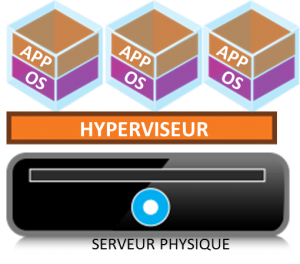
Mais il fallait aller encore plus loin dans la densification des infrastructures. Les éditeurs faisaient échos aux besoins toujours aussi nombreux et de plus en plus complexe en apportant des réponses qui ne simplifiaient pas pour autant les infrastructures.
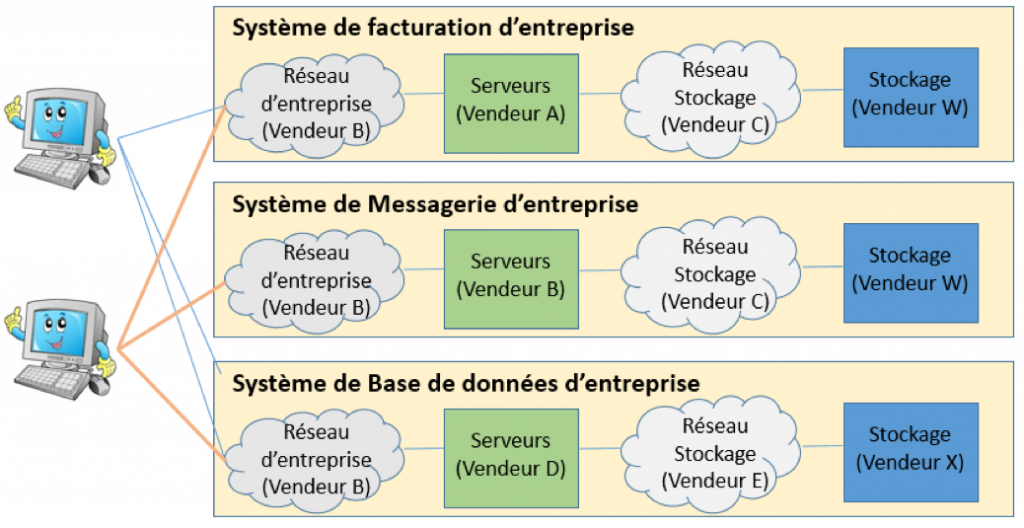
Nous en sommes à une nouvelle étape de simplification et d’optimisation des infrastructures en réduisant l’hétérogénéité : des éditeurs, des équipements et des contrats de maintenance. C’est à ce moment que sort du bois la technologie de convergence (Flexpod de Netapp, VCE, VMware,…) et l’Hyper-convergence HCI (Nutanix, VCE vXRail, Simplivity, Atlantis, …). Cette optimisation permet d’avoir dans un seul et unique boitier (Baie ou Appliance) aussi bien les serveurs, le stockage que les infrastructures réseaux nécessaires (IP ou stockage).
Construire son propre DataCenter sur des équipements traditionnels
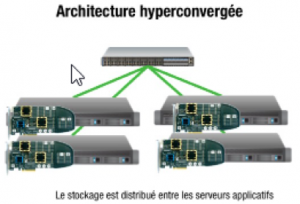
L’infrastructure classique continue de répondre aux besoins des entreprises et ça va continuer ainsi encore pendant un moment. Avec l’approche classique (Legacy) ou en convergé ou Hyper convergé l’édifice doit être construite sur de bonnes bases. Pour disposer de l’expérience du SDDC au service du DevOps, vient s’empiler des couches successives de services. Ce qui confère à l’infrastructure toute son importance dans l’édifice. L’approche Hyper-Convergée offre cette simplification technique recherchée.
Continuer sur son infrastructure classique ou basculer vers le convergé ou l’Hyper-convergé est une étape lourde et compliqué. Dans l’équation il ne faut pas oublier les aspects financiers : coûts d’acquisition mais aussi les couts indirects et cachés : prix de la maintenance, consommation électrique, refroidissement, etc …
 Le choix de la technologie pour le socle de toute la solution doit se faire selon plusieurs critères :
Le choix de la technologie pour le socle de toute la solution doit se faire selon plusieurs critères :
- technologique
- stratégique
- Financiers
Modélisons une situation financière dite idéale ou ; après un investissement initial faible, la courbe d’investissements des évolutions vient exactement se superposer à la courbe des besoins comme ci-dessous :
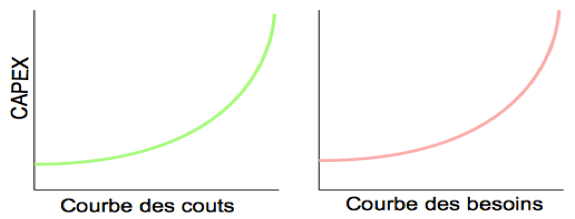
 En faisant figurer les investissements initiaux d’acquisition de matériel (incluant maintenant, etc) et la courbe des besoins dans une situation idéale nous avons le diagramme suivant. Les investissements suivent alors parfaitement les besoins. Ce cas de figure est possible aujourd’hui mais uniquement dans une approche en cloud ou il est possible de consommer en fonction des besoins et de payer à l’usage.
En faisant figurer les investissements initiaux d’acquisition de matériel (incluant maintenant, etc) et la courbe des besoins dans une situation idéale nous avons le diagramme suivant. Les investissements suivent alors parfaitement les besoins. Ce cas de figure est possible aujourd’hui mais uniquement dans une approche en cloud ou il est possible de consommer en fonction des besoins et de payer à l’usage.
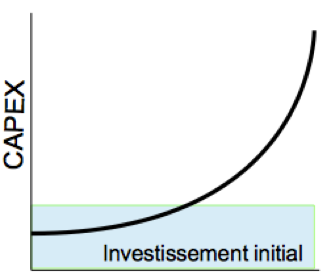
Appliquons la même méthode de modélisation pour comprendre les investissements dans une infrastructure traditionnelle.
Nous retrouvons l’investissement initial qui est incontournable et souvent relativement important. La croissance va pousser l’entreprise à continuer ses acquisitions en fonction des besoins et créer ainsi un impact relativement conséquent sur ses budgets. Par souci de simplification, je fais figurer les investissements matériels, le support, les renouvellements et les autres coûts adjacents comme un seul et même investissement.
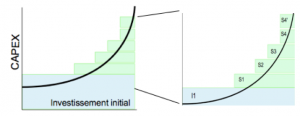
Pour donner une représentation concrète des couts liés à une infrastructure j’applique la méthode suivante :
- faire figurer la courbe des besoins (réguliers et constants pour simplifier)
- l’investissement initial
- L’ajout par couches successives des acquisitions qui accompagne les besoins.
Partant de cette représentation le coût en excèdent (ressource acheté et non utilisée) figure au-dessus de la courbe des besoins : I1 + S1+…S4+S4′
I1 = représente la surface des besoins non utilisés mais achetés.
S1+…S4+S4′ = représente le surinvestissement pour l’évolution de l’infrastructure.
S4′ = représente le surcoût lorsque la scalabilité de l’offre est arrivée à son extrême et que le coût de l’incrément est constant, incompressible et supérieur au besoin. Ce coût excédentaire est le plus notable car oblige l’entreprise à une acquisition excessive par rapport à un besoin pouvant être faible.
Les moments dans cette phase d’investissement successif qui sont les plus intéressants à observer sont :
– lorsque l’acquisition utile (sous la courbe) devient moins important ou égale que l’acquisition non-utilisée (au-dessus de la courbe)
– Pendant combien de temps le non-utilisé acheté est supérieur à l’utilisé acheté.
C’est à ce moment dans la vie de l’infrastructure qu’il faut financièrement anticiper la pertinence de la technologie sélectionnée. Une offre qui permet d’optimiser une infrastructure existante avec un impact minimum sur les budgets doit se trouver entre ces deux cas tout en restant le plus proche possible de la solution dite « idéale ». Dans le cas où le choix est de remplacer une infrastructure existante par une solution entièrement Hyper-convergée cela revient à racheter l’infrastructure initiale. Cette démarche sur un gros Datacenter risque donc d’être financièrement rédhibitoire.
La solution la plus réaliste modélisé dans l’exemple ci-dessous consiste à avoir un investissement initial faible (ou sinon plus faible qu’une infrastructure standard L1<I1) et ou l’augmentation des ressources se passe avec la granularité la plus fine en ajoutant ce qui est au plus proche de ce qui est nécessaire.
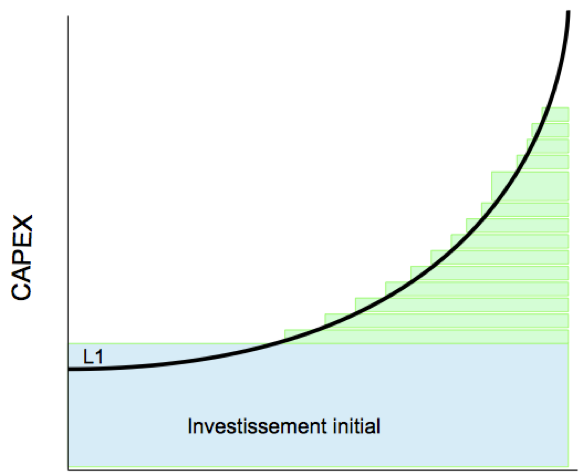
Le marché propose des solutions qui techniquement tienne vraiment la route mais ou l’investissement initial est aussi élevé que l’infrastructure traditionnelle. Si en plus la solution n’offre pas de modularité il devient compliqué de justifier l’acquisition d’un bloc complet pour répondre à un manque d’espace disque (par exemple).
Sans une « granularité fine » nous aurions le diagramme ci-dessous.
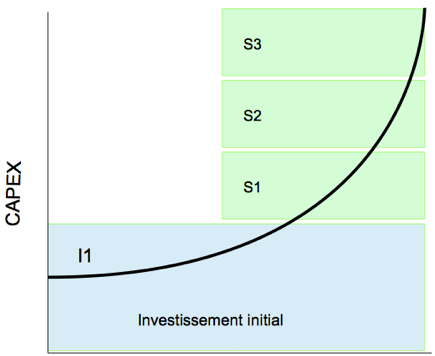
Au moindre besoin supplémentaire l’achat d’un serveur complet est nécessaire avec une surface d’investissement non utilisé très important. Même si c’est moins souvent que les autres solutions cela revient à racheter une maison quand j’ai besoin d’agrandir un peu ma cuisine.
Cet article vient à la suite des 2 articles suivant :
- L’hyper-convergence (Nutanix, Simplivity, VCE) et les entreprises ensemble face au paradigme du DevOps.
- Transition entre les infrastructures traditionnelles et le cloud natif avec l’hyper-convergence (VCE, Nutanix, Simplivity)
|
Pour suivre Emmanuel et pour plus d’informations sur son parcours et ses compétences : |
 Emmanuel Forgues
Emmanuel Forgues

