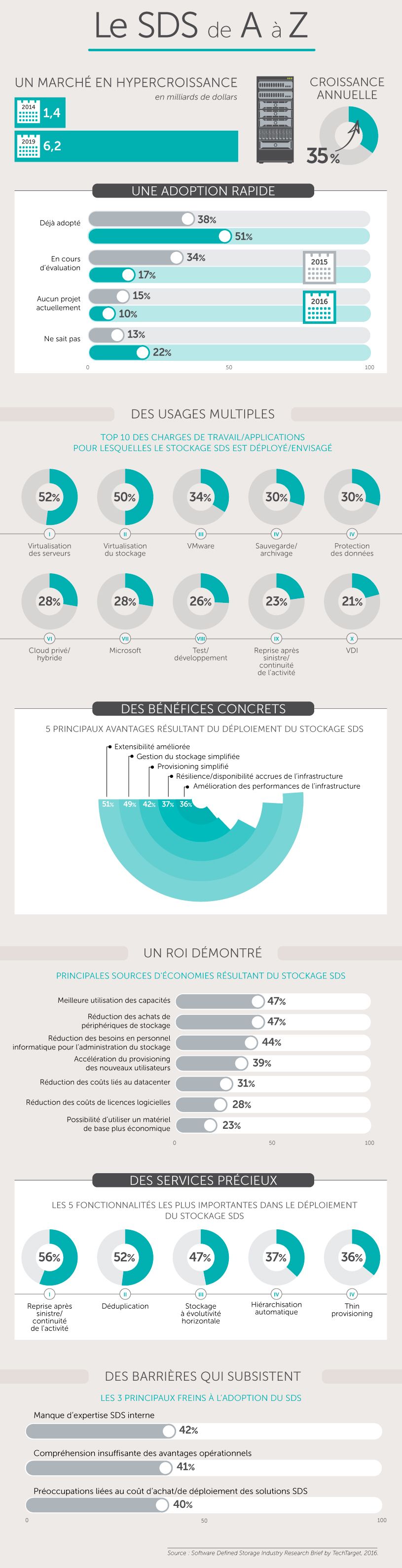
Le SDS de A à Z Le logiciel est partout. Serveur, stockage ou réseau, il n’existe plus un pan de l’infrastructure qui ne soit passé par la case « software-defined », au point que l’on parle aujourd’hui de « software-defined datacenter », voire même de « software-designed everything ». Mais toutes les couches du centre de données défini par logiciel n’en sont pas au même point. …