Pour faire suite à un article précédent (ICI), je souhaitais approfondir un élément important de notre profession : le rapprochement des équipes « Systèmes » & « Réseaux/sécurité ». Mais suite à des échanges, j’ai vite compris que ce mouvement était bien plus profond et avancé que je ne l’avais imaginé. C’est pourquoi, j’ai préféré axer cet article sur l’évolution du modèle « Admin » (Systems, réseau, bdd…) vers le « Full Stack Engineer ». Ce modèle apparaît dans notre métier et commence à être sérieusement théorisé dans de nombreux autres domaines (Production industrielle, recherche…).
Pourquoi prendre le temps de traiter de cette convergence entre les différents silos techniques historiques ? Car force est de constater que ce mouvement est loin d’avoir atteint une maturité suffisante auprès des équipes SI que je fréquente (Moyennes & Grandes structures SI). Évidemment, je ne veux pas faire de généralité mais je rencontre encore régulièrement des organisations aux équipes complètement hermétiques les unes aux autres. Dans les cas des équipes « Systèmes & Réseaux », le binôme fusionnel est rare !

Finalement, c’est dans les TPE que je retrouve les administrateurs les plus polyvalents. On pourrait donc en déduire que leur niveau global de technicité est plus faible dans chaque technologie ? Je dirais que ce n’est pas forcément le cas.
Comme expliquer ce phénomène ? C’est comme si la transdisciplinarité avait un rôle d’accélérateur de compétences techniques dans ce système complexe des SI où les problématiques des TPE sont finalement assez larges. Ce sujet, serait fort réjouissant à développer mais on s’écarterait un peu trop. (Ou pas, car n’est-ce pas l’objectif du FSE ? ). Pour aller plus loin sur la transdisciplinarité et les limites de l’hyperspécialisation, je vous conseille l’ouvrage suivant « La Transdisciplinarité : Manifeste » de Basarab Nicolescu, ici.
Mais revenons-en à notre « Full Stack Engineer ».
De nombreux challenges apparaissent et il faut maintenant nous réorganiser pour d’autres batailles à livrer : l’Automatisation des Datacenter et le DevOps. (Sujets d’une prochaine série d’articles ). Du coup, Il ne s’agit plus de prévoir les changements à venir mais bien de s’adapter pour survivre, et répondre aux attentes internes d’une transformation digitale devenue une nécessité. L’idée est donc d’avoir des ingénieurs avec un périmètre très large, des compétences fort acceptables dans de nombreux domaines et une ou deux spécialités.
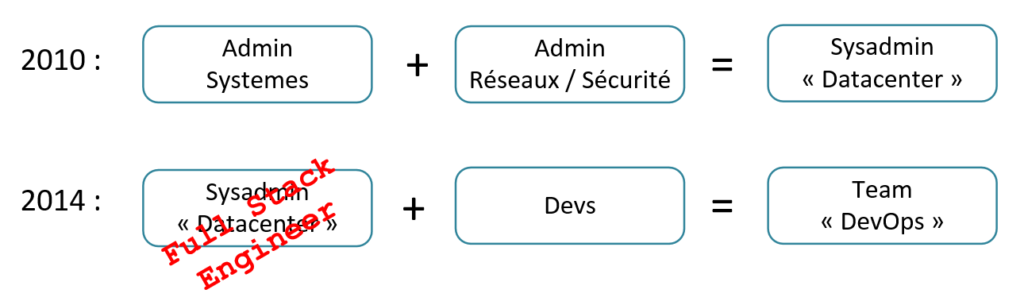
Dans un souci d’hyper-synthétisation de mon message, je me suis mis en 4 pour créer ce schéma :
Il est temps de vous présenter mes conseils pour permettre à son équipe d’appréhender le concept de « Full Stack Engineer ». J’ai décidé de les décomposer pour plus de clarté.
Pourquoi ?
J’ai déjà abordé ce point dans l’introduction mais il s’agit d’aller plus loin d’un point de vue opérationnel. Pour moi, devenir un « Full Stack Engineer », c’est un peu plus que d’être un bon généraliste. En effet, il s’agit de développer des compétences et d’acquérir des fonctions supplémentaires dans notre modèle.
- Assumer les choix d’architecture et des opérations techniques d’exploitation permettant à votre Datacenter d’assurer les contraintes de services et de performances associées. L’automatisation par exemple est une technique efficace pour diminuer les risques de production.
- Prendre en charge et savoir dialoguer avec les équipes de développement et/ou métier. Mais il n’est pas obligatoire de devenir un développeur ! Un exemple : Il n’est pas nécessaire de connaître / savoir utiliser Docker mais bien de comprendre en quoi la solution est bénéfique à ces équipes.
- Intégrer et être garant de la sécurité de votre SI. Difficile de ne pas voir le thème de la sécurité comme un bon exemple de compétences transverses nécessaires à l’ensemble des équipes. (Comme la gestion des certificats, Cycle de mise à jour…etc). Sans compter l’importance d’une sensibilisation globale à l’ensemble des équipes sur ces sujets. Vous êtes le premier Ambassadeur.
Pour finir sur ce point, devenir un Full Stack Engineer, c’est sur le plan humain :
- Répondre aux modèles et enjeux business/service de votre entreprise ou organisation publique. Difficile de débuter une transformation sans partager cette vision avec sa hiérarchie et vice-versa.
- Un épanouissement personnel : sans parler de l’évidente évolution de son employabilité, apprendre, comprendre et avoir des réussites est toujours un gain pour son équilibre personnel (les échecs en font également partie).
- L’esprit d’équipe et de partage est une source inépuisable de satisfaction !
Le parcours vers le FSE n’implique pas le remplacement des compétences, c’est au contraire une croissance des connaissances et de son périmètre.
Apprendre (Continuous Learning)
Certainement le point clé. Il s’agit dans de nombreux sujets de prendre connaissance des concepts.
- Les concepts. Voici une liste d’exemple de concepts intéressants à comprendre. Encore qu’il ne s’agisse pas d’avoir une maîtrise du produit ou de la technologie mais d’avoir une compréhension globale des nouvelles solutions composant le marché. Pour de nombreux produits des « courses » plus ou moins techniques sont disponibles mais il suffit parfois d’une bonne vidéo DailyMotion ou Youtube pour avoir une bonne vision de la solution. Tels que Microservices, Les containers (Docker, par exemple), Orchestration de container (Mesos/Mesosphere, OpenShift, Docker Swarm, Kubernetes), Le Cloud Public (AWS, Microsoft, OVH…), Ansible, Git, VXLAN, et JEAN PASS…. Je liste ici des concepts récents mais pour un ingénieur systèmes, il s’agit de connaître aussi les grands protocoles de routage comme OSPF, appréhender le fonctionnement d’ARP… Toujours se poser la question suivante : « Quel est le problème que cette technologie / fonctionnalité / configuration tente de résoudre ? »
- Avoir des « Use Cases/Business Cases » : Pour apprendre, rien ne vaut un bon « Use Case ». Il n’y a pas plus intéressant pour intégrer la connaissance et également dans le cas d’un « Case Business » pour porter à l’attention de sa hiérarchie les bénéfices acquis grâce au temps et aux moyens investis.
- Environnement de Démo : Mettre en œuvre dans son organisation un environnement iso-production devient essentiel. Il peut s’agir également de ressources disponibles dans le cloud public, de son propre site Web. Je connais que trop bien les freins à manipuler son infrastructure de production (et à juste titre).
- Démarrer par des objectifs simples et clairement définis. Exemple : Lorsque qu’un admin virtualisation débute dans l’automatisation, il faut commencer par pratiquer du PowerCli avec de petits TP vous permettant de faciliter votre administration journalière.
- N’ayez pas d’attentes trop élevées pour vos premiers projets.
- Fixez-vous des objectifs raisonnables.
- Il peut être utile de décomposer un problème plus important en plusieurs petits problèmes.
- Démarrer par des objectifs proches de votre zone de confort mais proposant des difficultés. Pour un ingénieur réseau par exemple, la gestion des switchs virtuels, distribués, des portgroups et vnics dans VMware ou pour un ingénieur système, utiliser régulièrement Wireshark, appréhender l’administration simple des équipements, aider à l’automatisation des switchs…
- Acquérir de la connaissance : Les supports ne manquent pas. E-learning, MooC, Blogs, et même des livres papiers. De nombreuses ressources gratuites sont à notre disposition. Dans l’histoire, jamais la connaissance n’a été aussi accessible et ce, quelle que soit sa catégorie sociale.
- Fréquenter les « Meetup » : Ces nouveaux formats qui apparaissent depuis quelques années sont fort riches en échanges. Ils sont très orientés technique, souvent d’un format court et détendu. Il ne faut pas hésiter à s’incruster à un meetup de développeurs et à revendiquer son appartenance au monde de l’opération. Vous verrez, ils sont très gentils.
- Langages et Scripting : Powershell, PowerCli, Bash, Python, Go… Il faut se lancer. Choisir un environnement et commencer par des actions simples et des tutos (Exemple l’article d’Erwann ICI).
- Attention au syndrome de l’imposteur ! (L’instant Wikipédia) : Cela peut être un vrai frein dans son accomplissement personnel ou la prise de responsabilité dans son entreprise.
- Des outils : Dans mon cas, j’utilise Slacks, Notes, et Trello/Planner pour structurer ma gestion de l’apprentissage. Mais je pense que c’est assez subjectif et que chacun s’organise en fonction des applications disponibles dans son organisation et de ses préférences en tant qu’utilisateur.
L’équipe et le partage
Pour revenir sur mes précédents propos le but n’est pas de devenir un spécialiste mondial de la discipline mais bien d’avoir une compréhension globale de nos Datacenter (public, privé ou hybrid). Il y a aura toujours des experts dans chaque discipline dans une team Devops mais l’idée est de comprendre les enjeux de chacun, de s’entraider et de pouvoir échanger ensemble sur les nombreux pièges et défis qui peuvent surgir sur la route d’un SI. (C’est le modèle des T-Shaped Skills, I-Shaped Skills et Dash-Shaped Skills, pour aller plus loin : ICI)
« If we all reacted the same way, we’d be predictable. And there’s always more than one way to view a situation. What’s true for the group is also true for the individual. It’s simple. Overspecialize and you breed in weakness. It’s slow death. « Ghost in the Shell » – 1995

Il faut savoir prendre des risques dans ces échanges. Rappelons-nous que nous n’apprendrons rien si nous ne sortons pas de notre zone de confort. Il faut accepter de ne pas tout savoir et que chaque personne dans votre équipe peut vous apprendre quelque chose et apporter sa pierre à l’édifice.
Il y a de nombreux moyens dans son organisation pour développer l’échange. C’est stimulant et cela nous oblige à augmenter la qualité de nos connaissances et de la communication :
- Écrire : Partager l’information accumulée lors d’un séminaire, d’une formation ou d’une maquette en écrivant un compte rendu synthétique mais technique. (Blog interne ou externe, Compte-rendu, REX interne lors d’une réunion…).
- Lire : Prendre le temps de lire et de comprendre, poser des questions. Dans le cas de communications internes, c’est simplement le juste retour à votre collègue qui a pris le temps de rédiger un compte rendu. Pour des publications externes, les flux rss par exemple sont un bon moyen d’avoir un flux d’informations de haut niveau et ciblé en fonction de ses besoins. Je reparlerai du « temps » à consacrer dans ma conclusion mais j’aime faire un lien avec les réunions « étranges » chez Amazon ou les PPT sont proscrits au profit de documents de 4 à 6 pages permettant d’avoir une connaissance approfondie du sujet qui devra être tranché. (A lire ICI).
Conclusion
J’enfonce des portes ouvertes avec ce sujet mais croyez-moi, je rencontre régulièrement des structures qui n’ont pas encore fait le pas d’une réorganisation des équipes infrastructures. Et je ne leur jette pas la pierre, faire bouger les lignes c’est toujours extrêmement complexe. Mais ce changement ambitieux ne peut se faire sans un investissement personnel et professionnel. Cela implique une hiérarchie consciente des enjeux et prête à investir financièrement (Moyens et Temps) pour amorcer ce virage.
Ce sujet est évidement indissociable de l’automatisation et du modèle DevOps. Avoir du temps pour notre formation, notre capacité à tester, rechercher des solutions techniques, les comprendre, les comparer et les mettre en œuvre est vitale pour notre métier, et au-delà, pour garantir son intendance stratégique dans cette transformation digitale qui nous impacte tous.
Avec ces enjeux du multicloud, une équipe multidisciplinaire et soudée est la meilleure garantie de réussite. En cas d’absence de synergies dans l’équipe, les efforts à fournir pour réussir deviennent considérables.

Sources :
Full Stack Journey : http://packetpushers.net/series/full-stack-journey/