





Hello et tout d’abord pour commencer je suis désolé pour ce retard de publication…
Dans le précèdent billet, il vous a été fait un bref rappel historique de Kuberrnetes ainsi qu’une présentation de son architecture. Je vous propose donc de débuter le billet de ce jour par une étude des différents concepts d’objets liés à Kubernetes.
A titre liminaire, il est important de rappeler que Kubernetes repose uniquement sur des concepts de REST API et que chacune des actions réalisées à l’intérieur de Kubernetes est de facto un appel à l’API Kubernetes présent dans le noeud Master.
YAMEUHLL?
Avant de parler des objets de Kubernetes, intéressons nous d’abord de plus près au langage YAML. Ce langage permet de représenter des données structurées. Le nom YAML signifie « YAML Ain’t Markup Language ». De ce fait, si on le compare aujourd’hui à un langage de Markup, comme par exemple XML, sa différence notable réside dans la composition de son langage accessible à un plus large public. Il peut être assimilé au format JSON mais néanmoins le YAML reste plus riche que le JSON en terme de structure de données.
A savoir :
- Il permet d’inclure plusieurs documents dans un seul fichier en les séparant par
--- ; - Il contient des types avancés comme les dates ;
- Il possède plusieurs manières d’écrire les textes multi-lignes.
L’écriture au format YAML va nous permettre principalement d’écrire des manifests kubernetes pour qu’ils soient interprétés par ce dernier. La syntaxe YAML est relativement rigide et structurée mais permet aussi une lisibilité claire.
Voici un exemple d’un manifest YAML pour déployer un pod dans une infrastructure Kubernetes :
—
apiVersion: v1
kind: Pod
metadata:
name: rss-site
labels:
app: web
spec:
containers:
– name: front-end
image: nginx
ports:
– containerPort: 80
– name: rss-reader
image: nickchase/rss-php-nginx:v1
ports:
– containerPort: 88
Dans cet exemple, et ce sans forcement parler des termes techniques pour le moment, nous pouvons apercevoir que l’indentation est relativement importante et de ce fait, permet de disposer d’une hiérarchisation des objets.
Par exemple:
containers: –> Objet (contient une liste d’objets)
– name: front-end –> Element « name » du 1er objet de la liste
image: nginx –> Element « image » du 1er objet de la liste
Pour rédiger un fichier YAML décrivant un objet Kubernetes, vous devez toujours commencer par insérer ces premières lignes :
apiVersion– Ce champ vous permet de spécifier la version de Kubernetes à utiliser. Kubernetes permet de supporter le multiple-API afin d’autoriser l’utilisateur à choisir sa version d’API.- Il existe trois sous-type d’API :
- version Alpha (v1alpha1)
- Dispose de nombreux bugs.
- API à ne pas utiliser dans un environnement de production.
- version Beta (v2beta4)
- le code est testé et la fonctionnalité est considérée comme sécurisée et stable.
- Non recommandé pour des environnements de production.
- version Stable (vX)
- API passé en version stable.
- Feature stabilisé.
- Recommandé en production.
- version Alpha (v1alpha1)
- Il existe trois sous-type d’API :
kind– Ce champ permet de définir le type d’objet Kubernetes vous allez créer :- Deployment
- Service
- Replica
- PersistentVolume
- etc…
metadata– Les metadatas permettent d’aider à identifier l’objet par son nom, son UID ou d’autres champs.
Contexte et Namespace
Lorsque vous déployer pour la première fois votre cluster Kubernetes vous devez définir un fichier de configuration qui est généralement placé dans $HOME/.kube, ce fichier s’appelle KUBECONFIG.
Il contient de nombreuses informations précieuses sur votre cluster et c’est grâce à ce fichier que vous pouvez agir avec les commandes kubectl sur votre Cluster.
Il contient notamment:
– Token d’authentification
– Username/password
– Définition des contexts
Je ne m’attarderais pas plus sur cette partie, que vous pouvez trouver sur le lien officiel pour configurer votre fichier KUBECONFIG notamment si vous disposez de plusieurs cluster Kubernetes .
https://kubernetes.io/docs/tasks/access-application-cluster/configure-access-multiple-clusters/
Dans mon exemple je dispose de plusieurs contextes sur mon mac (principalement car j’ai testé différents clusters K8S Minikube, Docker-for-Desktop, Dind, etc..)
kubectl config view
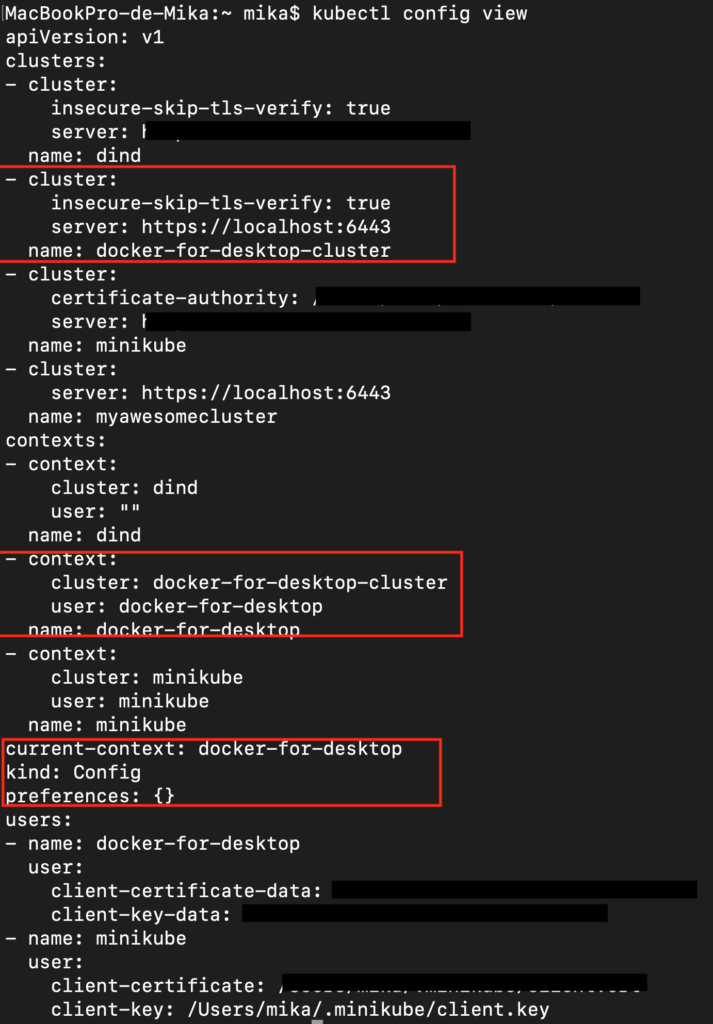
Kubernetes utilise les namespaces pour organiser l’ensemble des objets dans le cluster. Imaginons qu’un namespace est un folder qui permet de trier et de classer vos containers en fonction d’un environnement par exemple.
A chaque fois que vous exécutez une commande kubectl, vous pouvez préciser le namespace dans lequel vous souhaitez intéragir avec la commande –namespace= mon name space

Comment lancer mon premier container ?
Le lancement d’un container au sein d’un cluster Kubernetes se fait à travers l’objet POD. Le POD constitue l’unité atomique de déploiement dans Kubernetes, c’est l’objet le plus « petit » qui peut etre manipulable. Il a pour objectif de contenir un ou plusieurs containers, dans la plupart des cas aujourd’hui la relation entre container et POD est de 1:1.
La création d’un POD est définie sous forme de manifest YAML. Ce manifest va vous permettre de décrire l’état désiré de celui-ci. On appelle ce descriptif un deployment.
Il est important de retenir que plusieurs containers dans un POD partagent les mêmes ressources, stockage, système, réseau.
Les PODS sont liés au noeud où ils sont présents. Par conséquent, si un Node vient à disparaitre, Kubernetes déclenche la création des PODS sur un autre noeud, mais dans le même état et avec des propriétés similaires.
Chaque noeud dispose notamment :
– D’un container d’execution (docker engine)
– D’ un service nommé kubelet , en charge de veiller à la bonne exécution des PODS dans le NODE, qui échange avec le Master du cluster Kubernetes pour lui remonter l’état de santé des PODS.

Dans notre exemple nous allons prendre un manifest permettant de publier une application web de vote.
Cette application est relativement connue, à ce titre les sources sont récupérables ici :
https://github.com/mreferre/yelb
L’architecture de l’application est la suivante :

Notre manifest de déploiement des PODS est le suivant :
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: yelb-ui
namespace: yelb
metadata:
name: yelb-ui
namespace: yelb
spec:
replicas: 1
template:
metadata:
labels:
app: yelb-ui
tier: frontend
spec:
containers:
- name: yelb-ui
image: mreferre/yelb-ui:0.4
ports:
- containerPort: 80
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: redis-server
namespace: yelb
spec:
replicas: 1
template:
metadata:
labels:
app: redis-server
tier: cache
spec:
containers:
- name: redis-server
image: redis:4.0.2
ports:
- containerPort: 6379
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: yelb-db
namespace: yelb
spec:
replicas: 1
template:
metadata:
labels:
app: yelb-db
tier: backenddb
spec:
containers:
- name: yelb-db
image: mreferre/yelb-db:0.3
ports:
- containerPort: 5432
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: yelb-appserver
namespace: yelb
spec:
replicas: 1
template:
metadata:
labels:
app: yelb-appserver
tier: middletier
spec:
containers:
- name: yelb-appserver
image: mreferre/yelb-appserver
ports:
- containerPort: 4567
Pour me permettre de déployer correctement mes pods la commande à exécuter est :
kubectl apply -f yelb.yaml -n yelb
Pour m’assurer que mes pods soient correctement exécutés dans le bon namespace, voici la commande à appliquer pour récupérer l’état de mes pods :
kubectl get pods -n yelb
Comment exposer mon service à l’extérieur?
Quelques notions réseaux de bases avant :
- Tous les PODS peuvent communiquer entre eux sans NAT ;
- Tous les NODES peuvent communiquer entre eux sans NAT ;
- Durant le cycle de vie d’un POD, une adresse IP de type ClusterIP lui est attribuée ;
- Les containers d’un POD partagent le même réseau ainsi que le même namespace ce qui permet la communication intrapod sur localhost.
- Les services disposent d’une adresse IP unique persistante qui s’étend sur tout le cluster.
Lorsque l’on déploit un POD pour la première fois, on se rend compte que ce POD n’est pas accessible de l’extérieur.
Chaque POD déployé par défaut dispose d’une adresse de type « ClusterIP » comme mentionné ci-dessus.
Cette adresse IP est uniquement nécessaire pour la communication au sein d’un cluster. De ce fait, lorsque vous souhaitez exposer votre POD au monde extérieur vous devez utiliser l’objet SERVICE.
Voici les différents types d’adressage IP possibles dans Kubernetes :
- NodePort : Expose le service sur chaque IP de noeud sur un port statique. Il est possible de contacter le service NodePort depuis l’extérieur du cluster en demandant l’adresse IP <NodeIP>:<NodePort>
- ClusterIP : Expose le service sur une adresse IP interne au cluster. Le choix de cette valeur rend le service uniquement accessible depuis le cluster. C’est le type de service par défaut
- LoadBalancerIP : Expose le service en externe à l’aide d’un load-balancer d’un fournisseur de type Cloud. Les services Nodeport et ClusterIP sont automatiquement crées.
Lorsque l’on déploit un service pour exposer nos containers vers le monde extérieur, on commence par écrire un manifest YAML de type service. Par exemple, ici je souhaite exposer mon POD yelb-ui vers l’extérieur et mes autres pods resterons avec une adresse IP interne :
apiVersion: v1
kind: Service
metadata:
name: redis-server
labels:
app: redis-server
tier: cache
namespace: yelb
spec:
type: ClusterIP
ports:
- port: 6379
selector:
app: redis-server
tier: cache
---
apiVersion: v1
kind: Service
metadata:
name: yelb-db
labels:
app: yelb-db
tier: backenddb
namespace: yelb
spec:
type: ClusterIP
ports:
- port: 5432
selector:
app: yelb-db
tier: backenddb
---
apiVersion: v1
kind: Service
metadata:
name: yelb-appserver
labels:
app: yelb-appserver
tier: middletier
namespace: yelb
spec:
type: ClusterIP
ports:
- port: 4567
selector:
app: yelb-appserver
tier: middletier
---
apiVersion: v1
kind: Service
metadata:
name: yelb-ui
labels:
app: yelb-ui
tier: frontend
namespace: yelb
spec:
type: NodePort
ports:
- port: 80
protocol: TCP
targetPort: 80
nodePort: 30001
selector:
app: yelb-ui
tier: frontend
Une architecture scalable et fiable ?
La réputation de Kubernetes n’est plus à démontrer aujourd’hui, mais elle repose notamment sur un concept qui est le « Desirate State ». Concept qui fait que Kubernetes répondra toujours à votre exigence en terme de résilience et de haute disponibilité. Il cherchera le meilleur moyen pour rendre le service disponible. La notion de scalabilité en fait partie, on parle de deux types de scalabilité :
– Scalabilité Infrastructure –> ajout des workers
– Scalabilité Applicative . –> ajout des pods applicatifs.
Nous allons porter notre attention sur la scalabilité applicative, c’est un moyen de scaler « horizontalement » nos PODS pour répondre à une demande forte et imprévue. On parle également de scale-down ou scale-up, la capacité à pouvoir monter en charge ou descendre quand le besoin se fait ressentir.
Cette scalabilité applicative s’accompagne d’une notion dans Kubernetes qui est la notion de ReplicaSet. Un Replicaset est l’unique moyen pour scaler vos pods horizontalement afin d’absorber par exemple un pic de charge.
Pour vous assurer que votre replicaset réponde toujours à la même exigence définie dans votre fichier de déploiement, vous pouvez utiliser la commande suivante :
kubectl get rs
Cette dernière commande vous permet d’observer que l’état actuel correspond bien à l’état desiré.
Dans notre cas nous souhaitons augmenter l’état désiré du POD yelb-ui-7957d7bd56 à 5. Pour ce faire, nous allons donc modifier notre fichier de déploiement pour passer la valeur à 5 :
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: yelb-ui
namespace: yelb
spec:
replicas: 5
template:
metadata:
labels:
app: yelb-ui
tier: frontend
spec:
containers:
- name: yelb-ui
image: mreferre/yelb-ui:0.4
ports:
- containerPort: 80
Nous allons donc appliquer notre future configuration avec la commande
kubectl apply -f yelb.yaml
Vous pouvez vous apercevoir que nos pods ont été répliqués en 5 PODS différents.
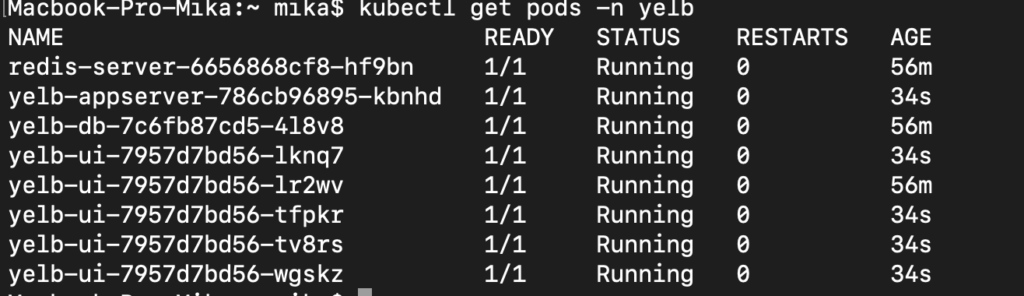
Ainsi, arrivé à ce stade, je peux, en effet, atteindre mon application relativement facilement.
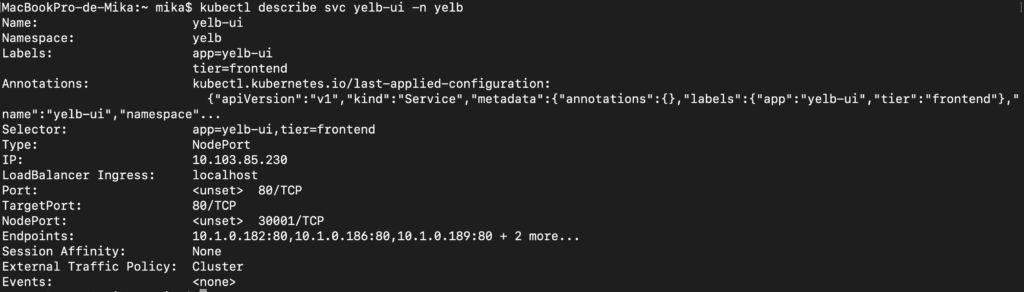
J’exécute la commande qui me permet de découvrir le port d’écoute de mon service yelb-ui :
kubectl describe svc yelb-ui -n yelb
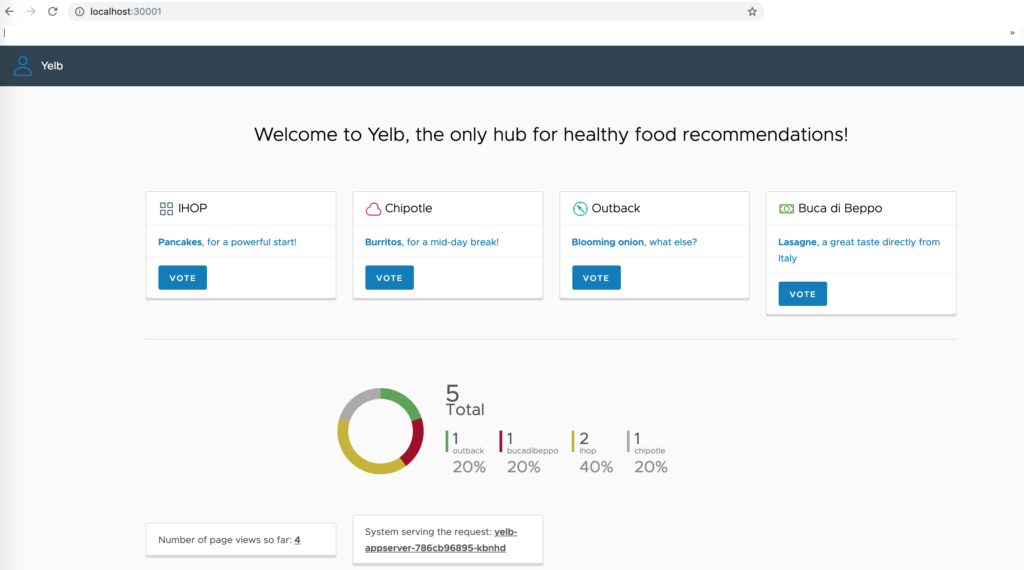
J’ouvre mon navigateur et je rentre l’URL :
http://localhost:30001
La raison d’utiliser localhost résulte du fait que j’exécute mon cluster Kubernetes sur mon mac et donc je ne dispose que d’un seul node.
Ingress & Ingress Controller ?
Super, me diriez-vous notre application fonctionne et on a scaler horizontalement les containers de type frontend.
On dispose donc d’une résilience de mes PODS frontend et donc d’une répartition de charge.
Néanmoins si vous avez bien fait attention notre service appelé « yelb-ui » est de type NodePort.
Pour rappel si notre service est de type NodePort c’est qu’il est uniquement accessible sur l’adresses IP de votre node K8S, ce qui n’est pas très pratique lorsque l’on dispose de plusieurs node au sein d’un Cluster K8S.
De plus, une seule adresse IP suffit pour distribuer potentiellement l’ensemble de mes sites WEB. L’objectif étant de jouer sur les « virtualhost » (petit clin d’oeil à apache avec les virtualhost)
C’est à ce moment précis que l’on va commencer à parler d’ingress controller dont le but est de faire l’interface entre vos utilisateurs (les requêtes web) et les services kubernetes associés.
OK mais dans le titre il y a aussi « Ingress », car un « Ingress » est tout simplement une règle qui permet de relier une URL à un service. Un ingress controller est un reverse proxy qui implémentera des règles d’ingress.
Aujourd’hui c’est la méthode la plus efficace pour router vos différentes requêtes web sur vos différents services Kubernetes qui exposent vos PODS.
L’ingress controller vous permet de disposer d’un load balancer de L7 au format container afin de pouvoir répartir la charge entre vos différentes applications.
Note : Un Ingress controller ne permet pas de router directement votre trafic vers les PODS mais bien vers vos services. Au préalable, il faudra bien vérifier que vous avez crée votre service.

Principalement il existe plusieurs types d’ingress controller reconnus dans le monde des containers :
- Nginx
- HAPROXY
- Traefik
Pour plus de simplicité nous allons utiliser HELM pour déployer notre ingress-controller. L’avantage d’utiliser HELM c’est un peu comme les blueprints dans vRA. HELM est une solution qui package plusieurs déploiements, services, etc ce qui vous permettra en une exécution de déployer tout ce qu’il vous faut.
Pour déployer le chart HELM NGINX la commande à utiliser est :
helm install --name nginx-ingress --namespace nginx-ingress stable/nginx-ingress
Une fois l’installation de votre ingress effectuée vous devez vous retrouver avec deux PODS :
- L’ingress-controller
- Default Backend
En effet l’ingress-controller NGINX a besoin d’un « default-backend » pour fonctionner correctement.
Une fois que notre ingress-controller est déployé il nous reste donc à écrire une règle de routage appelée ingress rules. Cette règle nous permettra de définir la méthode de routage vers mon service applicatif YELB.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
name: nginx-ingress
spec:
rules:
- host:
http:
paths:
- path: /
backend:
serviceName: yelb-ui
servicePort: 80
On applique notre fichier d’ingress-rules dans notre namespace applicatif avec la commande suivante :
kubectl create -f ingress.yaml -n yelb
Pour vérifier que notre régle est bien implémentée la commande à utiliser est la suivante :
kubectl get ingress -n yelb

Il ne reste plus qu’à ouvrir notre navigateur et insérer l’url http://localhost
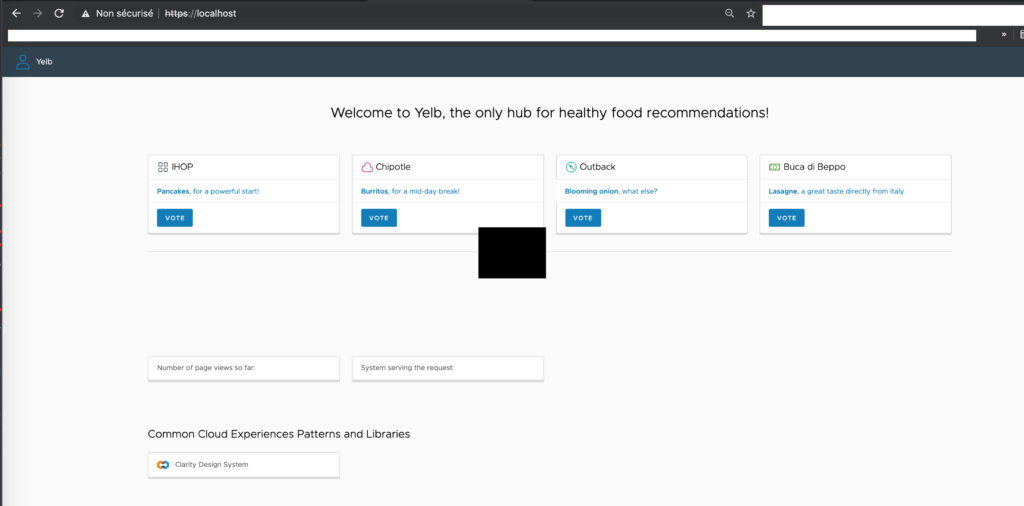
Les lecteurs qui auront l’oeil pourront constater, en effet, que mon URL en http est redirigé directement en https car dans la configuration interne de mon ingress-controller il y a une redirection pour forcer l’ensemble des sites en HTTP à passer en HTTPS.
J’espere que cet article vous aura aidé à mieux comprendre certains objets de Kubernetes.
Le prochain article viendra compléter certaines notions qui n’ont pas été abordées ici.
N’hésitez pas à commenter, afin de m’améliorer et de vous proposer des contenus de plus en plus pertinents.
Je vous remercie d’avoir pris le temps de me lire et je vous dis à trés bientôt.
Mikael



