





Bonjour à toutes et à tous ! Après plusieurs mois à vouloir commencer à écrire un article c’est chose faite, me voilà ainsi contributeur du blog MyVMworld. Je tenais à remercier l’ensemble de la crew de m’accueillir.
Pour mon premier article, nous allons parler de Kubernetes. Un mot très en vogue dans l’IT en ce moment, mais au final quelle valeur ajoutée apporte t-il concrètement ? Je vais essayer d’être le plus clair possible dans cette introduction à Kubernetes. Dans les prochains posts, nous rentrerons plus en détails dans les parties techniques.
Un focus sera notamment réalisé sur le produit PKS (Pivotal Container Service) de VMware qui propose une offre relativement intéressante.
Les containers
Revenons un peu en arrière et parlons quelques minutes des containers. Principalement je me focaliserais sur l’origine des containers de type Linux sans forcement parler de technologie pour le moment, il en existe pléthore (OpenVZ, LXD, RKT, Windows Server Container, Hyper-V Container, etc..).
La virtualisation par container se base sur la virtualisation Linux appelée LXC (Linux Container).
Un container linux est un ensemble de processus complètement isolés du système permettant d’exécuter une ou plusieurs applications. Chaque conteneur partage le même OS ce qui peut être un avantage comme un inconvénient (tous dépend l’angle de vision DEV ou SECOPS).
Les conteneurs Linux représentent une nouvelle évolution de la manière dont nous développons, déployons et gérons des applications. Ils permettent d’assurer une efficacité en terme de portabilité et de contrôle de version, ainsi un conteneur Linux mobilise moins de ressources qu’une machine virtuelle.
Le conteneur ne virtualise pas l’environnement d’exécution (comme le processeur, la mémoire vive ou le système de fichier…) ce qui implique qui ne virtualise pas le systéme d’exploitation.
C’est pour cela que l’on parle de « conteneur » et non de machine virtuelle (VM).

En outre, le besoin d’adopter les conteneurs s’est fait rapidement sentir par les entreprises principalement du fait de leur compatibilité native avec n’importe quelle type de plateforme.

A la suite d’une adoption massive des technologies de conteneurs par les entreprises et la communauté, ces dernières on fait un constat relativement flagrant : Gérer un ou plusieurs conteneurs sur son PC est relativement simple, mais lorsque qu’il s’agit de les mettre dans un environnement de production avec toutes les contraintes que cela implique (supervision, sécurité, résilience, etc..) la complexité s’est faite ressentir par les équipes opérationnelles !
Les questions des Ops sont très vites arrivés :
- Comment démarrer les conteneurs ?
- Comment exposer les services conteneurisés ?
- Comment gérer les conteneurs arrêtés ou en erreur ?
- Comment gérer la tolérance à la panne ?
- Comment gérer la mise à l’échelle (scale-up & down) ?
- Comment gérer les mises à jours des composants ?
- Comment faire pour que les développeurs soient plus autonomes dans les environnements?
La réponse à toutes ces questions est l’utilisation d’un orchestrateur de conteneurs.

Kubernetes
Kubernetes est à l’origine d’un programme de Google appelé Borg System sorti entre 2003 et 2004, avec seulement quelques ingénieurs de Google pour le développer. Il est aujourd’hui présenté comme la référence d’orchestrateur de conteneur.
Mais d’où vient le mot Kubernetes ?
Kubernetes est à l’origine un mot Grec, voulant dire timonier ou pilote c’est la racine de gouverneur en cybernetique. On donne souvent l’abréviation K8S à Kubernetes. Cette abréviation résulte du fait que ubernete est composé de 8 lettres, d’où leur remplacement par le chiffre 8.
La naissance d’une success story ?
2003-2004 : Création de BORG SYSTEM
Initialement considéré comme un petit projet sur lequel 3 à 4 ingénieurs ont planchés dessus. Ce système de gestion de cluster pouvait exécuter des centaines de milliers de tâches à travers de nombreux clusters et donc par conséquence gérer des milliers de machines.
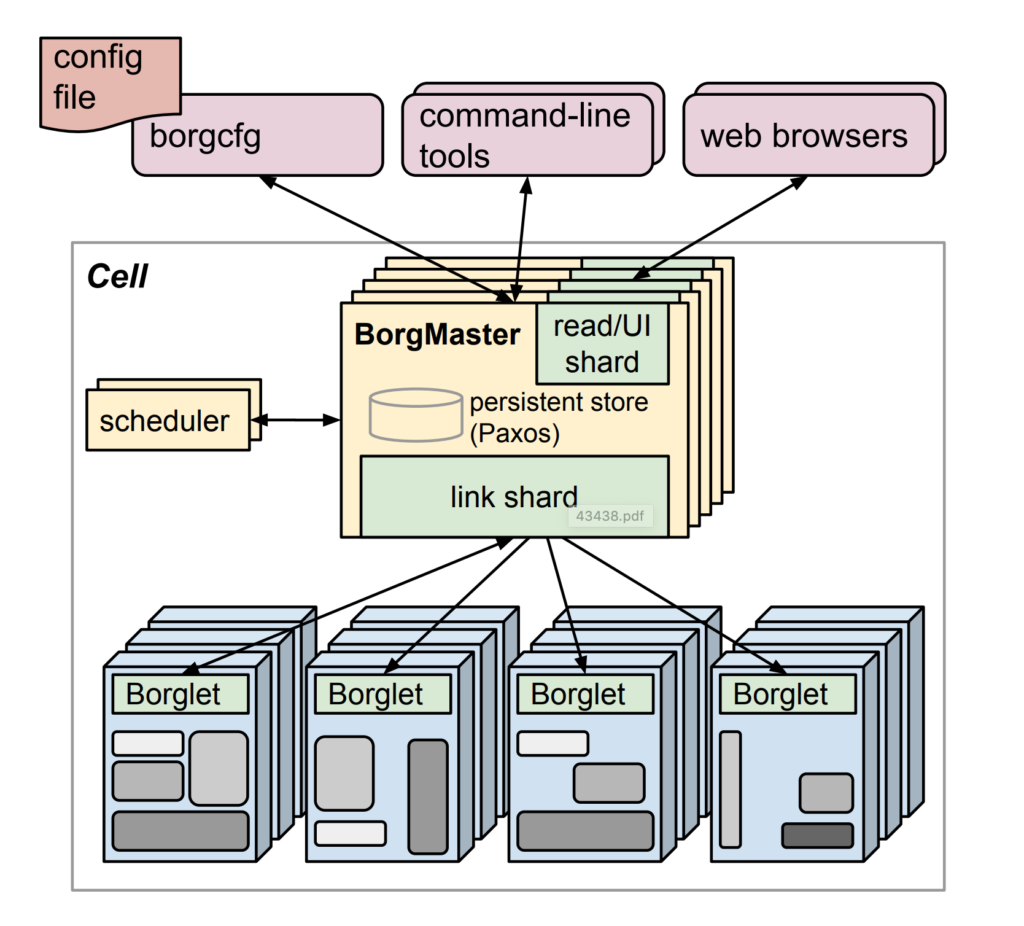
Pour en savoir plus sur Borg System :
https://storage.googleapis.com/pub-tools-public-publication-data/pdf/43438.pdf
2013 : OMEGA
Google annonce un nouveau système management de Cluster appelé OMEGA, vous trouverez ci-dessous le whitepaper pour plus d’informations: https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/41684.pdf

2O14 : Introduction de Kubernetes
Google introduit officiellement Kubernetes comme une version open-source du système Borg. Les premières releases ainsi que les premiers commits arrivent très rapidement sur Github.
Juillet 2014:
Microsoft, Redhat, IBM & Docker rejoignent la communauté Kubernetes https://cloudplatform.googleblog.com/2014/07/welcome-microsoft-redhat-ibm-docker-and-more-to-the-kubernetes-community.html
2015 Happy Birthday Kubernetes :
Google avec le partenariat de la Linux Foundation et de la CNCF release la première version de Kubernetes en version 1.0. Rapidement l’éco-système continue de s’étendre avec la naissance de nouveaux partenariats importants (Openshift, Deis, etc..).
2016: Kubernetes Fast
L’année de l’accélération de Kubernetes. Kubernetes release pas moins de 4 versions de 1.2 à 1.5 dans la même année. Pour la petite anedocte Pokemon Go, qui tourne sur GCP(Google Cloud Platform), a été le premier exemple de projet à utiliser la puissance des conteneurs avec Kubernetes.
https://cloud.google.com/blog/products/gcp/bringing-pokemon-go-to-life-on-google-cloud
2017: Adoption de Kubernetes par les entreprises
Kubernetes a été adopté relativement rapidement par les entreprises du fait de sa maturité. Néanmoins, une nouvelle version majeure v1.6 a été publiée avec la gestion du RBAC en version beta ainsi que d’autres fonctionnalités. C’est également l’année où les conférences KubeCon & CloudNativecon sont les plus attendues par les développeurs et réunissent 1500 utilisateurs à travers le monde.
2018: Adoption de Kubernetes par les Cloud Provider
L’adoption de Kubernetes a été faite par les différents Cloud Providers. Nous retrouverons les produits en mode « as a service » notamment :
– AKS ( Azure Kubernetes Service)
– EKS (Amazon Elastic Container Service for Kubernetes)
– GKE (Google Kubernetes Engine)
Architecture
L’architecture de Kubernetes est constituée de deux composants :
– Master Node
– Worker Node
Ces composants peuvent tourner sur n’importe quel type d’environnement comme :
– machine virtuelle
– Barre metal
– Cloud Provider (en mode as a Service)
Pour une résilience optimale dans un environnement de production il est fortement conseillé de disposer de 3 master nodes, permettant une réplication des données de la base etcd.
La communication réseau de Kubernetes peut se baser sur des technologies SDN de type overlay. Nous y reviendrons plus tard dans un autre billet.
Kubernetes Master node :
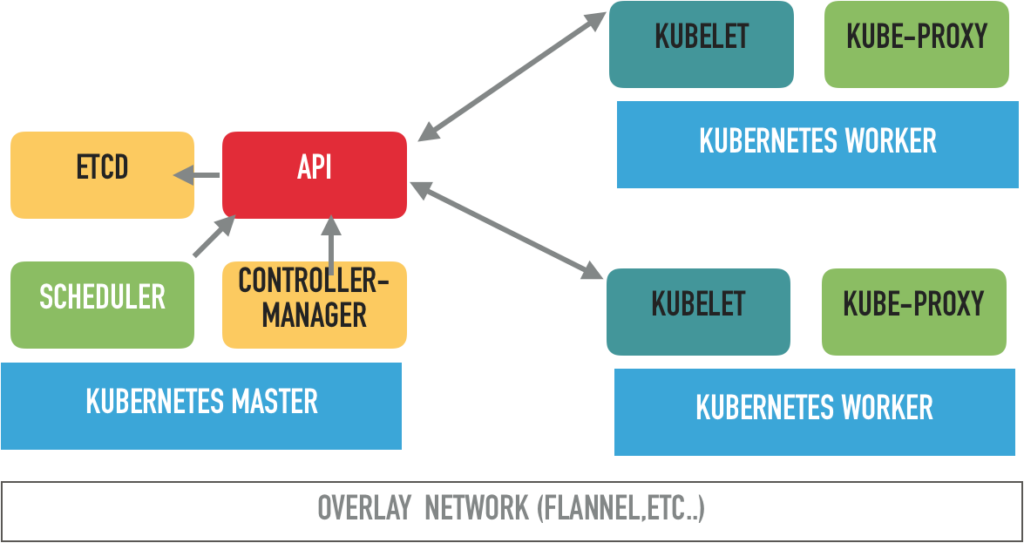
Le master node dispose de plusieurs fonctionnalités permettant de distribuer l’information aux worker nodes.
- ETCD : Stockage des informations du cluster Kubernetes
(comme le nombre de pod, leurs états, le nom des namespaces, etc..) - API Server (Kube-API) est le composant central qui reçoit et traite l’ensemble des requêtes API du cluster (pod, service, replication, etc..) C’est également le seul composant qui communique avec la base etcd.
- Controller-Manager lance plusieurs process distincts en tâche de fond pour réguler la charge des nodes et assurer un routage optimal. Lorsque un changement est fait dans la configuration d’un déploiement (changement image). Le contrôler-manager est en charge de surveiller l’état et de lancer le nouvel état désiré.
- Scheduler : permet de programmer les pods en fonction des ressources sur les différents noeuds (worker node). Il doit pouvoir avoir la visibilité de la charge totale de tous les modes pour s’assurer que le pod dispose toujours de ressources suffisantes pour s’exécuter.
Node (Worker) :
Les worker nodes sont présent pour hoster vos conteneurs. La limitation des workers nodes se situe aux alentours des 5000 (on a de la marge…).
Deux services sous forme de conteneur sont présents dans chaque worker node, à savoir :
- Kubelet : Service principal sur le noeud pour s’assurer que l’état des pods soit correctement exécuté et desiré. Le Kubelet échange directement avec l’API Master pour rendre des comptes sur l’état des pods.
- Kube-Proxy : En charge d’intercepter les requêtes venant du monde extérieur (hote) vers les containers directement. Il est également responsable de l’exposition des services vers le réseau externe.
Conclusion
J’espère que cet article vous aura aidé pour poser les bases de Kubernetes et comprendre l’architecture de celui-ci dans ses grandes lignes. Le prochain article sera dédié à la compréhension des objets Kubernetes.

