



Comment installer votre propre LLM sur votre machine et déconnecté d’internet?

Le futur se construit avec VMware ARIA
Hello la French VMware communauté, Cela faisait un petit moment que je n’avais pas écrit d’article sur MyVMworld, mais je suis de retour avec de très bonnes nouvelles et aujourd’hui nous allons parler de VMware Aria. Alors beaucoup d’entre vous (clients, partenaires, collègues) me posent souvent la question pourquoi VMware a changé le nom de sa Cloud Management Platform (CMP), …

Il était temps !! un mini Lab avec Maxtang NX6412
En 2022, lors du VMware Explore à Barcelone, j’ai eu la chance de recevoir un cadeau incroyable de Cohesity en tant que vExpert : un Maxtang NX6412. Ce PC compact est devenu la base de mon lab VMware, et avec quelques ajouts astucieux… NX6412 – PC Compact Les spécifications de ce boîtier compact sont les suivantes : Le défi avec …

Security October : Un Voyage Cyber avec Splunk, Rubrik et VMware à Aix en Provence
Hey, le VMUG sera de passage à Aix ! C’est avec enthousiasme que nous vous convions à Aix, le 3 octobre prochain au magnifique Domaine de Gaogaïa à Aix en Provence pour un VMUG France. Une matinée qui promet une plongée passionnante dans le monde de la cybersécurité, de la récupération après sinistre et des solutions de pointe proposées par …

USERCON FRANCE 2023 : quand Paris devient l’épicentre des techs et de l’IT de demain
VMUG UserCon France 2023 : Le rassemblement incontournable de l’IT et des technologies à Paris. Le 19 septembre 2023, la capitale française sera le théâtre du VMUG UserCon France. Dépassant de loin le simple statut de rassemblement des utilisateurs des solutions VMware, cette rencontre est l’occasion pour les éditeurs de technologie reconnus mondialement d’offrir un aperçu de leurs dernières innovations, …
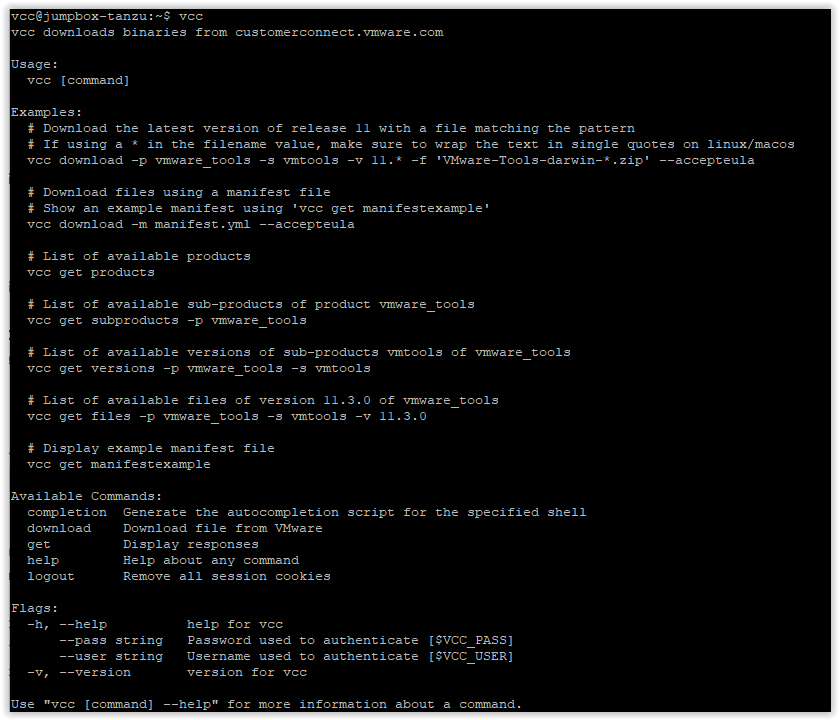
VMware Customer Connect CLI (VCC) : Téléchargement des produits VMware en ligne de commande
Il y a quelque temps (mois) maintenant, j’ai vu passer sur mon Twitter, un message de mon ami Timo concernant un nouvel outil permettant de récupérer les différents produits VMware (vCenter, NSX, VMware Tools, Tanzu…) directement en ligne de commande. Mais quel est le but de ces commandes, me direz-vous ?! Dans le cas de VMware Tanzu, cela peut …

LLM : La révolution technologique qui marque l’avènement d’une nouvelle ère
Comment fonctionne les LLM et plus particulièrement ChatGPT

C’est l’heure de Tanzu (Timezone)
Nous allons continuer la configuration du fuseau horaire pour les machines virtuelles Tanzu Kubernetes Grid (TKGm), suite au premier article sur la configuration des serveurs de temps (NTP). Cela n’est pas un problème majeur, mais peut être gênant en cas d’analyse de log ou encore de tâche CronJob K8S ! GMT+0 Tout d’abord, nous vérifions la configuration existante en nous …
Nomination des vExpert 2023 – France
Cette semaine, VMware vient d’annoncer la liste des vExpert pour 2023. Rappel : Le programme vExpert s’adresse aux personnes ayant contribué de manière significative à la communauté des utilisateurs VMware. Le principe : les candidats au programme vExpert doivent s’engager à partager leur passion et leurs connaissances pour la technologie VMware et pour son écosystème. Les vExperts peuvent s’exprimer au travers de blogs personnels, d’intervention en public (VMUG, …

Intelligence artificielle, un bouleversement plus important qu’Internet ?
Comment l’intelligence artificielle va révolutionner Internet et nos usages ? Dans cet article, nous allons décrypter une partie de son fonctionnement et démystifier l’IA avec des mots simples. »
Il manquait une majuscule à « Internet » au début de la phrase et une virgule après « article » pour séparer la phrase en deux parties distinctes.
C’est l’heure de Tanzu (NTP)
Un retour d’expérience concernant la configuration de l’heure dans TKGm (Tanzu Kubernetes Grid Multi Cloud => avec un Management Cluster). En effet, lorsqu’on souhaite renforcer sa configuration, comme toujours la documentation est à lire (RTFM). Le sujet est découpé en 2 articles, un premier sur le partie configuration des serveurs de temps (NTP) et le un second (à paraître) sur …