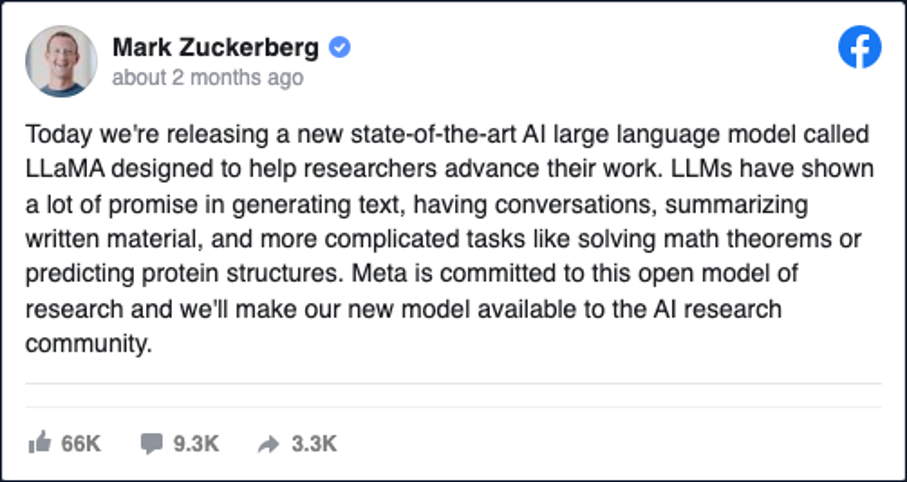
Récemment, la division IA de Meta, Meta.AI, a publié son propre modèle de langage (https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) qui a été fuité sur quelques sites. Ce modèle, appelé LlaMa (Large Language Model Meta AI), compte 65 milliards de paramètres et se décline en plusieurs versions :
- Llama 7B (7 milliards de paramètres)
- Llama 33B (33 milliards de paramètres)
- Llama 65B (65 milliards de paramètres)
Llama est également utilisé dans d’autres domaines, tels que la recherche d’informations, la planification de voyages, la réservation de restaurants, et bien plus encore. Grâce à sa capacité à comprendre le langage naturel, Llama est capable de traiter des requêtes complexes et de fournir des réponses précises, ce qui en fait un outil précieux pour de nombreuses industries.
En résumé, le fonctionnement de Llama de Meta repose sur des modèles de langage profondément entraînés et une base de connaissances massive pour comprendre les requêtes des utilisateurs, trouver des réponses pertinentes et générer des réponses en langage naturel. Cette technologie est utilisée dans une variété de domaines pour fournir des réponses précises et personnalisées à des millions d’utilisateurs dans le monde entier.
Marc Zuckerberg a reconnu que l’IA pourrait très rapidement surpasser le Metaverse, Il a également indiqué que la nouvelle priorité de l’entreprise est l’élaboration de technologies d’intelligence artificielle, qui sera « l’investissement le plus important » de l’entreprise pour les mois à venir, et l’intégration à l’ensemble des produits du groupe.
Une alternative à GPT ?
Des chercheurs de Stanford ont réussi à reproduire le modèle de GPT-3.5 en utilisant le modèle de Llama (Meta), qui compte 7 milliards de paramètres. Ils ont obtenu un taux de réussite équivalent à celui de GPT-3.5, mais à un coût incroyablement bas de 600 $. Cette avancée pourrait potentiellement présenter un défi pour ChatGPT.
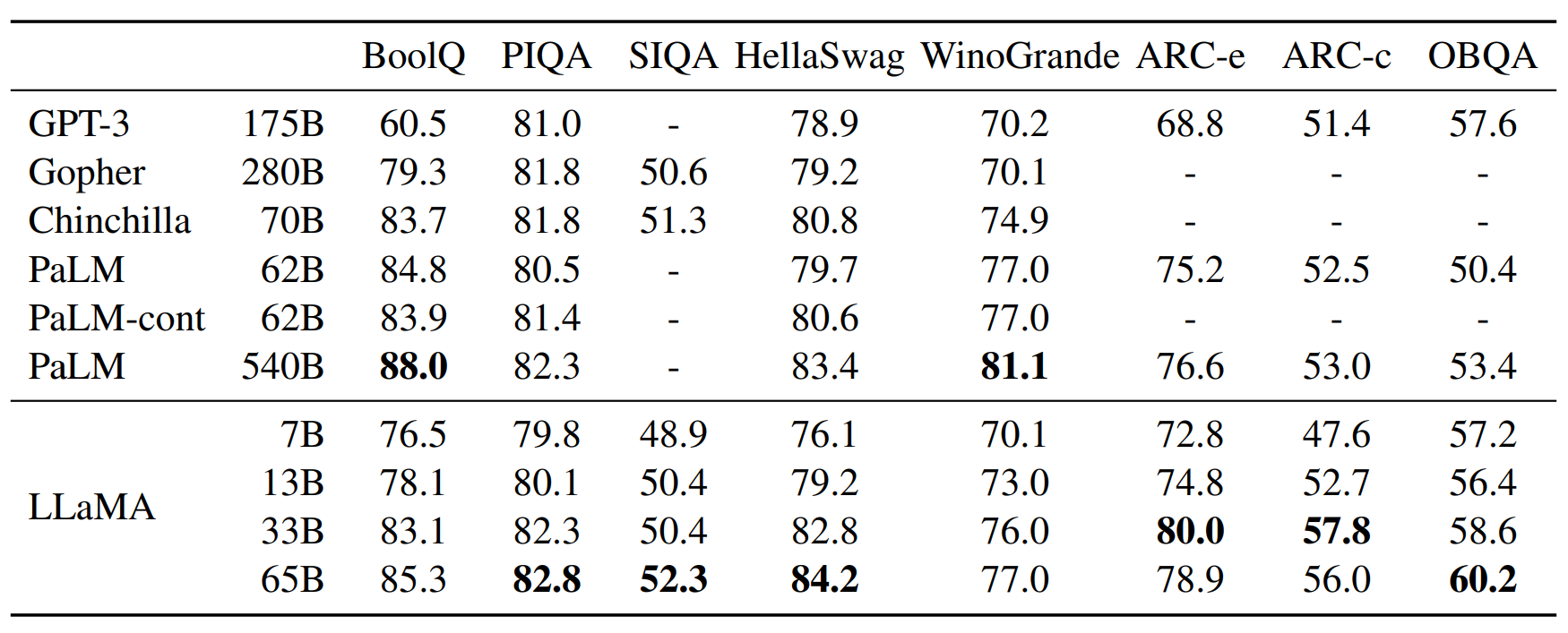
Si vous souhaitez comparer les différents modèles de LLM, je vous recommande de consulter cet article qui présente les différents benchmarks de performance : lien vers l’article.
Il est clairement observable que Llama surpasse tous les autres modèles en termes de performance, même avec un nombre inférieur de paramètres en entrée. Ceci n’est pas
Ce qui est particulièrement intéressant, c’est que cette IA peut être exécutée directement sur votre ordinateur (PC/MAC/Linux), en exploitant la puissance de calcul de votre processeur, sans même avoir besoin d’une connexion Internet et ni de GPU 🙂
Bien sur des alternatives il en existe comme Alpaca ou Vigogne (plus fine tuned pour le FR) mais je ne pourrais pas tous couvrir dans cet article je vous invite à faire vos recherches si vous souhaitez utiliser d’autres modele comme Alpaca qui est plus léger que Llama.
A titre d’information:
- LLaMa 7B (Celui qu’on va utiliser) : environ 13 Go en version originale 16 bits, 4 Go en version 4 bits.
- LLaMa 13B : environ 26 Go en 16 bits, 8 Go en 4 bits.
- LLaMa 30B : 65 Go en 16 bits, 20 Go en 4 bits.
- LLaMa 65B : 130 Go en 16 bits (à n’utiliser si vous avez 512 GB de RAM sur votre machine 😀 )
- Alpaca : 4 Go, modèle en 4 bits
- vigogne 7B : 13 Go en 16 bits (dérivé de LLaMa), 4 Go en 4 bits.
- gpt4all : 4 Go en 4 bits (plusieurs modèles, “filtrés” ou non)
Comment installer Llama sur son poste ?
1. Installer les prérequis comme python nécessaires sur votre poste pour faire fonctionner correctement Llama, dans mon cas j’utilise un mac et je vais utiliser la fonction des repos brew pour nos prérequis
brew install [email protected]
brew install pipenvSi vous avez un Mac, il faudra bien installer XCODE pour compiler en C++
xcode-select --install2. Cloner le projet llama dans votre dossier favoris
git clone https://github.com/ggerganov/llama.cpp3. Executer la commande make dans le répertoire
make3. Créez maintenant un sous-dossier appelé 7B dans le dossier models et entrez-y.
4. . Téléchargez ensuite le modèle (manuellement ou via la ligne de commande à partir de ce lien. Cela peut prendre quelques minutes.
wget https://huggingface.co/decapoda-research/llama-7b-hf/resolve/main/tokenizer.model5. Executer la commande suivante afin de convertir le modele
python3 convert.py models/7B/./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin q4_06. le modele de 7B de parametre doit être enfin pret dans votre dossier, nous allons pouvoir l’executer avec quelques parametres supplémentaires afin de le tuner :
./main -m ./models/7B/ggml-alpaca-7b-q4.bin --color -f ./prompts/alpaca.txt -ins --n_parts 1 --temp 0.8 --top_k 40 -n 5000 --repeat_penalty 1.3 --top_p 0.0Désormais nous avons un vrai « Chat-GPT » (aussi puissant que GPT-3.5) directement sur notre poste sans connexion internet.
L’interface est un peu brut, mais il est toujours possible de rajouter une interface Web par dessus…
Enjoy ! 
Ce n’est que le début, accroche-vous pour la suite:
Depuis la sortie de ChatGPT, de nombreuses alternatives ont fait leur apparition comme vous avez pu le constater, à commencer par Microsoft Bing qui utilise GPT-4 comme moteur par défaut. Cependant, nous anticipons que les modèles de langage actuels deviendront obsolètes d’ici moins de 5 ans. À ce sujet, je vous recommande de lire un article mentionné par Yann Lecun.
En parallèle, Nous sommes entrés dans une nouvelle ère, l’ère des agents conversationnels basés sur l’IA, conçus pour accomplir les tâches qui leur sont assignées. Cependant, il est important de souligner que cette avancée pourrait potentiellement devenir destructrice si elle n’est pas contrôlée….
Comment installer Auto-GPT & Agent-GPT sur votre poste ?
Auto-GPT est la révolution car il permet d’executer des streams à travers des agents conversationnelle qui sont capable de réflechir et d’atteindre le ou les objectifs que vous lui avez fixer.
L’idée est d’arriver à enchaîner les actions avec GPT-3 et GPT-4, sans qu’un usager n’ait à intervenir à chaque étape. Voilà pour la théorie. Dans la pratique, le projet est encore balbutiant et la supervision humaine n’est jamais loin.
Vous pouvez installer Auto-GPT directement sur votre poste mais cela requiere quelques prérequis avant de le faire fonctionner, si vous souhaitez ne pas trop vous embeter avec cela il existe une version en ligne ici https://godmode.space/
- Installer sur votre terminal Git, Python3, docker (uniquement si vous voulez faire l’install avec docker),
brew install git python3 docker2. Avoir une clé OpenAI valide rendez-vous sur le site : https://platform.openai.com/overview
3. Vous devez rentrer un moyen de paiment afin que votre clé OpenAI fonctionne
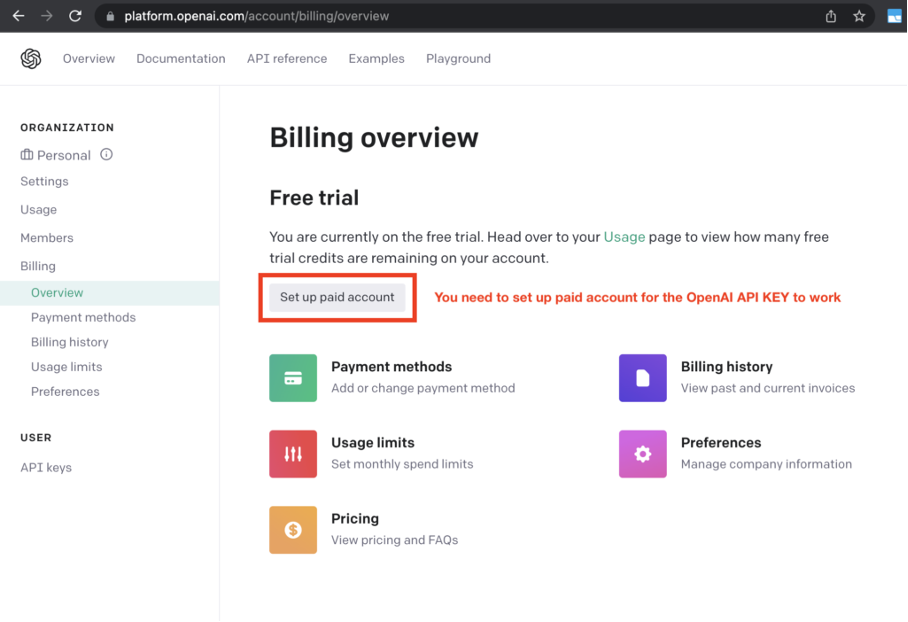
4. Créer une nouvelle clé OpenAI puis conservez la quelque part.
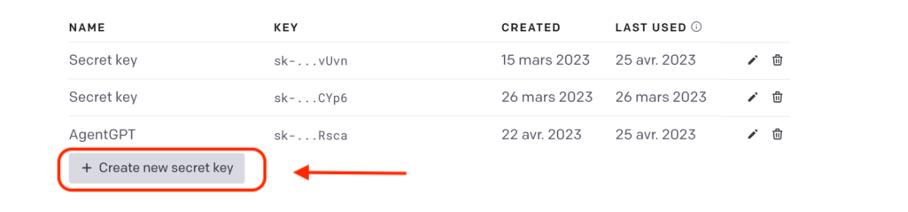
5. Cloner le projet Auto-GPT depuis votre terminal favoris
git clone -b stable https://github.com/Significant-Gravitas/Auto-GPT.git6. Créez une copie de .env.template et appelez-la .env ; si vous êtes déjà dans une fenêtre de commande/terminal :
cp .env.template .env. 7. Télécharger et installer les dépendances avec la commande :
pip install -r requirements.txt7. Trouvez la ligne qui mentionne OPENAI_API_KEY=. Après le =, saisissez votre clé API OpenAI unique sans guillemets ni espaces. Saisissez toutes les autres clés API ou jetons pour les services que vous souhaitez utiliser. J’utilise également PINECONE pour les DB vectoriels sur lequel vous pouvez vous inscrire sur le site https://www.pinecone.io/
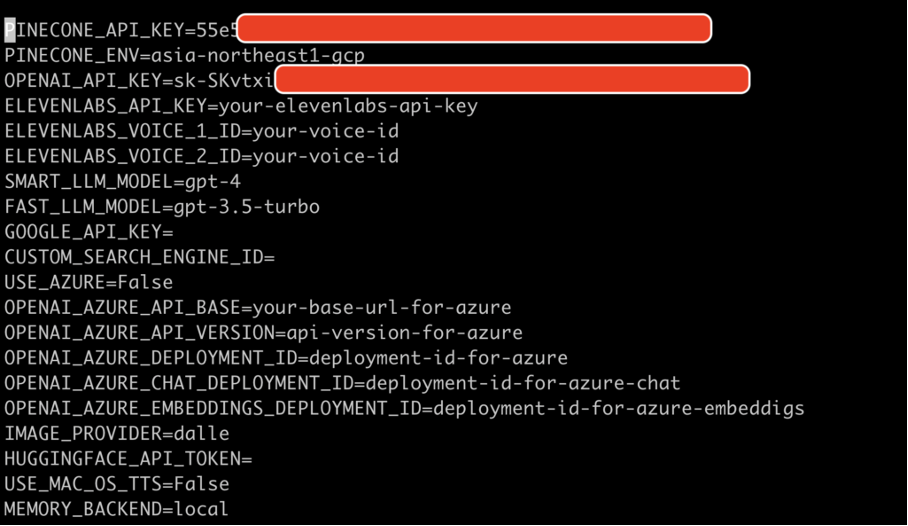
8. Désormais vous pouvez lancer Auto-GPT en ligne de commande dans un mode simple avec la commande :
python3 scripts/main.py9. Un mode dit « Continuous mode » existe mais attention il est très dangereux avec le parametre suivant :
python3 scripts/main.py --continuousDésormais vous pouvez lui fixer un ou plusieurs objectif a réaliser :
- Trouve moi les dernieres tendances en matiere d’intelligence artificielle
- Réalise un résumer de cette recherche
- consolide le dans un fichier

Quelques exemples réalisés avec Auto-GPT
L’utilisateur demande à AutoGPT de créer un site web en partant de rien (from scratch) et notamment de créer une page login/sign up et de la styliser avec Bootstrap. L’agent IA autonome est en capacité de créer le site en 10 minutes seulement.
Conclusion:
Depuis la rédaction de cet article, plusieurs réactions majeures ne se sont pas fait attendre. Google, a riposté en annonçant son propre concurrent pour rivaliser avec Chat-GPT, nommé Bard.
Ce nouveau modèle de langage est basé sur la technologie Palm2, démontrant l’engagement constant de Google dans l’innovation et la pointe de l’IA. En faisant écho à son long héritage de solutions technologiques révolutionnaires, Google vise à renforcer sa position dans le domaine de l’intelligence artificielle avec Bard.
OpenAI a annoncé également GPT-4 avec 175 milliards de parametre qui est naturellement plus puissant et plus performant que GPT-3 et ainsi que Llama & Alpaca.
Ainsi, Google, avec Bard, Microsoft avec Bing et OpenAI avec ChatGPT s’engage une fois de plus dans la course à l’IA, cherchant à établir de nouvelles normes et à repousser les limites de ce qui est possible. Cela promet une concurrence intense et stimulante dans le domaine de l’IA conversationnelle, bénéfique à la fois pour les développeurs et pour les utilisateurs finaux.